Computer Vision
Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model (2024.01)
- -
- Accepted at ICLR 2024 Conference
- LoRA 업그레이드 버전
- 저자는 SAM의 한계점을 명시하면서 이를 해결하기 위한 method를 제안함.
이때, 좀 더 efficient하면서 여러 도메인에서 general하게 쓸 수 있는 LoRA 기반의 새로운 PEFT method를 제안
Convolution Meets LoRA: Parameter Efficient Finetuning for Segment Anything Model
The Segment Anything Model (SAM) stands as a foundational framework for image segmentation. While it exhibits remarkable zero-shot generalization in typical scenarios, its advantage diminishes when applied to specialized domains like medical imagery and re
arxiv.org

INTRODUCTION
- 최근들어 Foundation model들이 매우 발전되고 있는데, 그중에서도!! SAM(Segment Anything Model)은 image segmentation 분야에서 독보적인 foundation 모델로 자리잡고 있음
- 그러나! SAM이 모든 real-world에서 잘되는 것은 아님
- 특히 medical, agriculture, remote sensing 등의 특정 도메인에서는 실패하기도 함.
- SAM의 근본적인 한계점 존재
- image encoder는 plain ViT이므로, vision-specific inductive biases 부족
- SAM은 binary mask(오직 배경과 분리)로 학습 => low-level segmentation => high-level image semantic 정보를 포착하기에는 부족
- SAM의 근본적인 한계점 존재
이런 SAM의 한계점을 해결해보자!
- PEFT(Parameter Efficient FinTuning)하게 갈꺼야~~ => SAM의 모든 parameter를 학습시키지 않고(=freeze), 적은 양의 parameter만 학습(=hot)=> 기존의 parameter를 freeze 시키므로, 사전 지식을 유지
새로운 PEFT method: Conv-LoRA 제안
- (Key 1) 기존 LoRA layer 사이에 가벼운 convolution block 삽입
- convolution 고유한 특징인 vision-specific inductive-bias 가져갈 수 있음
- (Key 2) MoE(Mixture-of-Experts) 컨셉 구현
- 객체의 크기 너무 다양 => iamge feature를 다양한 크기로 보면 좋겠다!
- 여러 experts를 두고 > 각 expert가 다른 scale의 feature를 보고 > 각 결과를 합쳐주면 > 하나의 feature도 다양한 크기로 볼 수 있음
- (Key 3) mask decoder에 multi-class prediction을 수행하는 MLP 추가
- multi-class semantic segmentation 수행 가능
METHOD

(1) Conv-LoRA
- LoRA의 중간부에 Convolution operations 삽입
- Convolution 연산은 image-related local prior(=conv의 장점)를 넣어줄 수 있기 때문에 사용
- 단순 Convolution block 대신, 새롭게 MoE-Conv block 제안

- MoE-Conv

MoE-Conv - 구성 : N개의 expert networks + gating module
- gating module : 입력 데이터를 가지고 dynamic하게 expert를 고름
- expert networks : feature map을 특정 크기로 키워서 봄(expert마다 보는 크기가 다름)
- 3개의 step으로 구성
- interpolation - 특정 크기로 reconstruct
- convolution
- subsequent interpolation - 원래 크기로 복구
- 3개의 step으로 구성

- 왜 MoE를 사용했는가??????
- 기존의 보편적인 모델들은(=Swin Transformer, PVT .. ) 주로 Multi-scale을 사용함.
- MoE는 특정 experts를 고르기 때문에 multi-scale보다 비교적 computational cost가 적음 => efficient!!~~
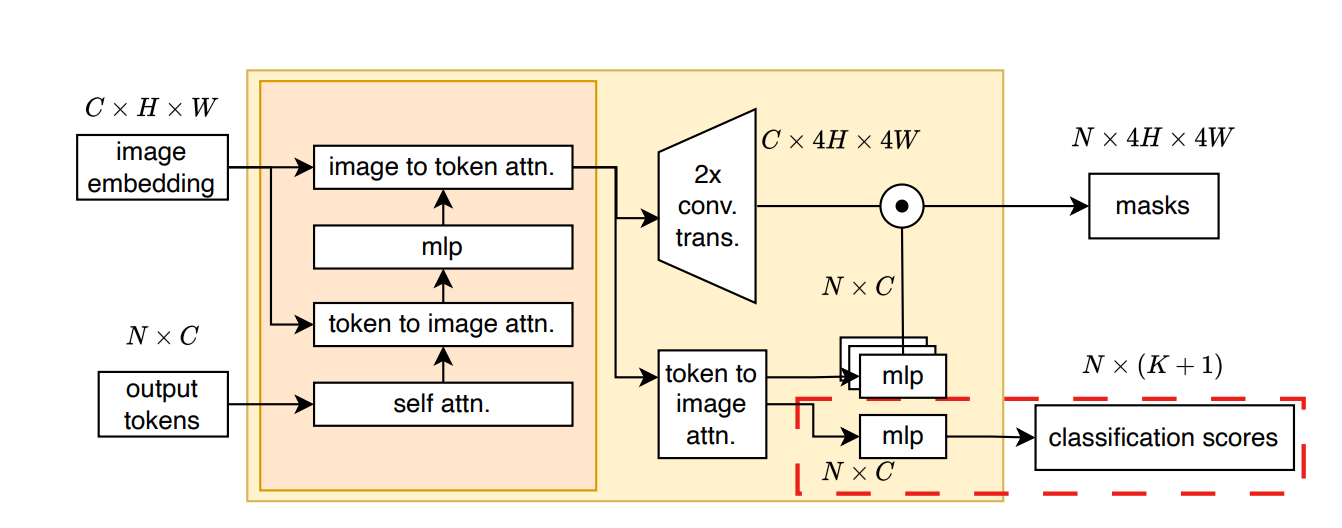
(2) End-To-End Multi-class Segmentation with SAM
- SAM에게 prompt는 flexible이라는 매우 큰 무기지만, 특정 작업에서 end-to-end로 활용하기에는 힘듬
- SAM을 automate하게 변경
- prompt encoder freeze => 항상 같은 prompt token 제공
- multi-class segmentation을 수행할 수 있도록 변경
- classification branch를 추가 - MLP로 구현
- 이 브랜치에서 나온 class score를 통해, 해당 mask에 대한 class 예측 가능(단순 background/foreground에서 다양한 class로 예측 가능해짐!)
Experiments
- 4개의 real-world domain - Medical/Natural/Agriculture/Remote sensing 환경에서 실험 수행
Binary-Class Semantic Segmentation

- Medical, Natural, Agriculture, Remote Sensing > 4개의 domain에서 모두 Conv-LoRA가 좋은 성능을 보임(general하게 좋은 성능)
- 이때, Medical domain의 CVC-612, ISIC 2017 dataset에서는 Domain Specific 모델이 더 좋은 성능을 보임
- SAM trained from scratch 성능이 안좋음 => SAM의 사전 지식이 확실히 down-task 성능에 영향을 줌
Multi-Class Semantic Segmentation

'Computer Vision' 카테고리의 다른 글
| [SAM] 코드 리뷰 (1) | 2023.12.29 |
|---|
Contents
소중한 공감 감사합니다